Блогов што го читате е резултат на работните групи по вештачка интелигенција, каде што ние студентите Стефан Најдовски и Христијан Горков, запишани на прв циклус студии на Факултетот за Информатички и Комункациски Технологии - Битола под менторство на Проф д-р Костандина Вељановска. и асистентот М-р Дарко Пајковски.
Нашата тема на обработка ќе ви ја претставиме детално, низ илустрации а резулатот од нашето мини истражување е мал модел кој може да преведува македонски текст.
Содржина
- Вовед
- Што е токен? (Token)
- Токенизирање (Tokenization)
- Dataset
- Секвенца во секвенца
- Позиционо кодирање (Positional embeddings)
- Внимание
- SentencePiece
1. Вовед
Целта на овој блог е со двојна природа, првенствено е наменета да научиме како функционира Transformer архитектурата, делот кој ја направи науката за вештачки неуронски мрежи посериозна, практична и достапна за секого, најголема примена има во Large Language Models како GPT, Claude, Mistral, LLAMA…
Втората цел ни е да ви претставиме мал модел кој знае да преведува кратки реченици од македонски јазик на англиски јазик.
На крајот има и demo од проектот, што може да се користи практично, со одредени лимитации.
Секако нашата имплементација тука ќе биде многу пати поедноставна, но есенцијално идејата е иста, скоро целосно базирана врз оригиналниот труд Attention is All You Need.
Целта нема да биди: Generative Pretrained Transformer (GPT), имплементација на целосен Large Language Model (LLM), е далеку покомплицирано со теорија и уште потешко за имплеметнација, сакавме да бидиме јасни за која е целта.
Она што ќе го имплементираме и објасниме, ќе биди:
Sequence to Sequence Vanilla Transformer или на кратко Seq2Seq Transformer.
Ќе гледаме да балансираме со технички жаргони и да објасниме интуитивно и со примери за секој да може да не следи.
Ви препорачуваме да имате некоја блага основа за полесно следење, за тоа што е Neural Network и што е тоа Natural Language Processing, исто препорачливо е познавање на основи на веројатност и статистика.
Доколку сакате да научите или сте љубопитни и жедни за знаење слободно погледнете:
Корисни ресурси за почетници
2. Токен
Овој збор кај нас би бил преведен како лексема или жетон, во англиската (програмерската) литература e дефиниран како атомична (неделива) единица за репрезентација нa текст. (искрено не сме сигурни дали го имаат истото значење на македонски или општо во лингвистиката).
Должината на оваа единица е произволна и зависи од проблемот што сакаме да го решиме.
Се сретнува во повеќе должини:
- Реченица (пример: Здраво Македонијо!)
- Дел од збор (пример во вистински јазик би биле слоговите).
- Збор(пример: здраво).
- Карактер (пример: а).
- Бајт (пример: ASCII или UTF енкодиран карактер).
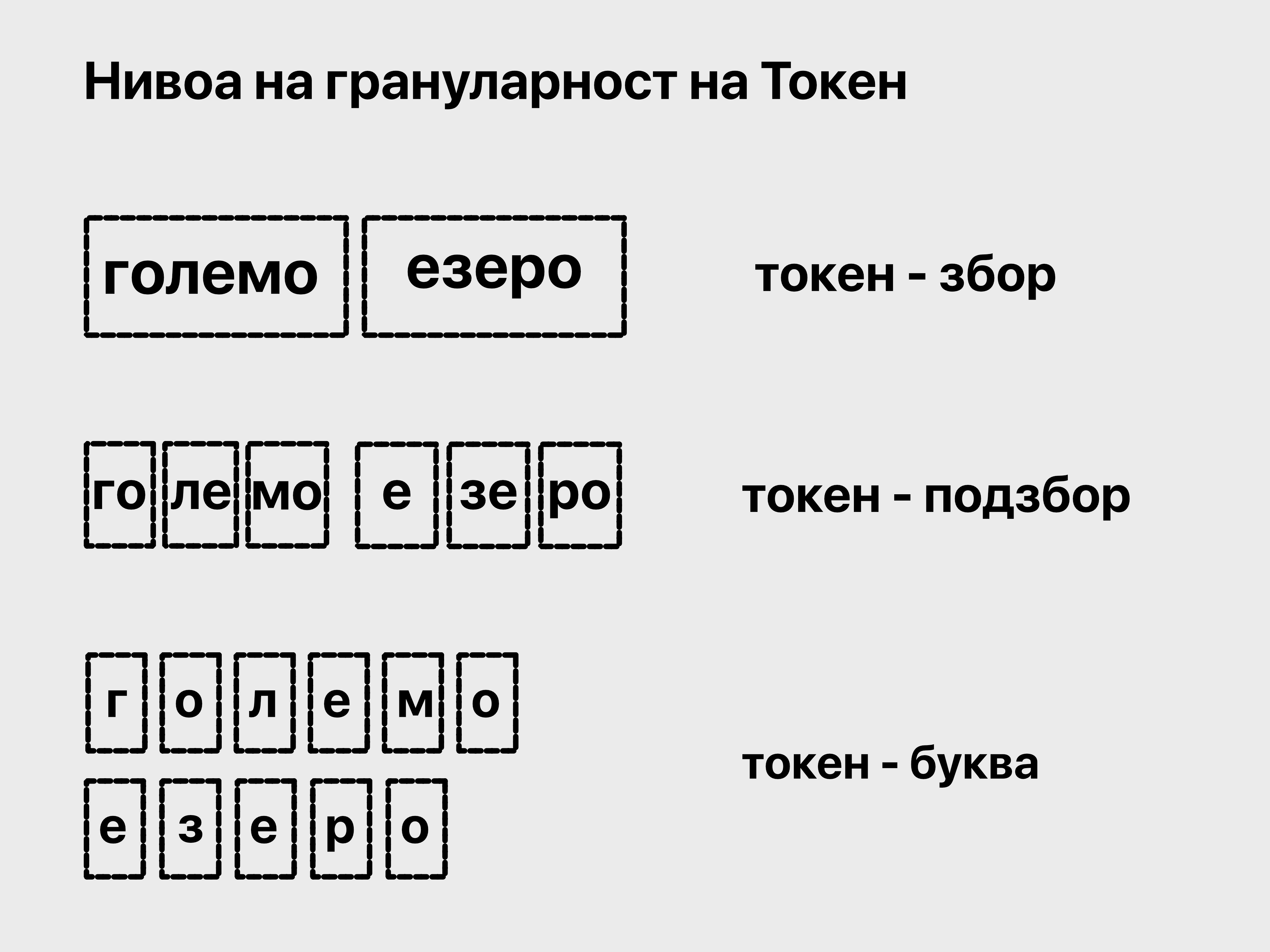
3. Токенизирање
Е процесот на претворање на текст (во нашиот случај македонска кирилица) во токени, со тоа што подоцна истите тие ќе бидат претставени како вектори за моделот да може да ги процесира.
Типови на токенајзери:
- со правила (Rule-based) (токен-збор,токен-буква), најнеоптимален.
- Научен (Learned) тип:
- Byte-Pair Encoding (BPE)
- WordPiece
- Униграм.
ние го користиме Unigram, со помош на SentencePiece библиотеката.
4. Dataset
За оние кои не се запознаени Data set претставува колекција од податоци, најчесто организирани во табела.
Изглед на нашата “табела”:
здраво hello
ние сме студенти. we are students.
јас сакам да учам. I want to learn.
...
За тренирање на нашиот модел ние искористивме корпус кој е достапен на интернет, секако со дозвола на авторите кои можите да ги најдите тука.
Податоците за тренирање ги зачувавме во формат наречен Tab-Separated Value или TSV на кратко, со помош на библиотеката pandas во Python.
Во првата колона ги ставивме речениците на македонски јазик, во втората колона ги ставивме преведените реченици на англиски јазик, дел од речениците беа преведени од почеток, остатокот од другите користевме Google Translate и локални LLM модели со техника на дестилација да враќа формат кој е прифатлив.
Валидација правевме со неколку примероци за квалитетот. Но дефинитивно сметаме дека не е најдобар начин за превод.
Како резултат добивме релативно мал data set од околу 500 илјади преведени реченици.
Дистрибуција според должина на реченици:
Со помош на овие македонско-англиски парови го трениравме моделот.
5. Севенца во Секвенца (Sequence to Sequence).
Seq2Seq се користи за обработка на природни јазици NLP.
Во нашиот случај ќе го користиме за превод од македонски на англиски, мислиме дека е добар баланс помеѓу нешто што е корисно да направиме за нашиот мајчин јазик ,нешто што не е само теорија и нешто што може да се научи, три во едно!
Пред да се појави трансформер архитектурата, механизмите за “внимание” биле ограничени со GRU или LSTM и користењето на RNN-Recurrent Neural Networks.
6. Позиционо кодирање (Positional embeddings)
Оргиналната имплементација користи статични (фиксни) позициони вградувања.
За да се пресмета вредноста на едно позиционо вградување (3.5 во оригиналното истражувње).
Авторите ги користат функциите синус и косинус:
\(PE(\text{pos}, 2i) = \sin\left(\frac{\text{pos}}{10000^{\frac{2i}{d_{\text{model}}}}}\right)\)
\(PE(\text{pos}, 2i+1) = \cos\left(\frac{\text{pos}}{10000^{\frac{2i}{d_{\text{model}}}}}\right)\)
Енкодирањето зависи од 3 вредности:
- pos - позицијата на векторот
- i - индексот внатре во векторот
- d_model - димензијата на внесот
Позиционалните вградувања се користат за информирање на трансфомерот на која позиција се наоѓаат векторите за внес. Тие се додаваат на секоја вредност во векторот посебно.
class PositionalEncoding(nn.Module):
def __init__(self, emb_size: int, dropout, maxlen: int = 10000):
super(PositionalEncoding, self).__init__()
den = torch.exp(- torch.arange(0, emb_size, 2) * math.log(10000) / emb_size)
pos = torch.arange(0, maxlen).reshape(maxlen, 1)
pos_embedding = torch.zeros((maxlen, emb_size))
pos_embedding[:, 0::2] = torch.sin(pos * den)
pos_embedding[:, 1::2] = torch.cos(pos * den)
pos_embedding = pos_embedding.unsqueeze(1)
self.dropout = nn.Dropout(dropout)
self.register_buffer('pos_embedding', pos_embedding)
def forward(self, token_embedding: Tensor):
return self.dropout(token_embedding +
self.pos_embedding[:token_embedding.size(0),:])7. Внимание
class Seq2SeqTransformer(nn.Module):
def __init__(self, num_encoder_layers: int, num_decoder_layers: int,
emb_size: int, src_vocab_size: int, tgt_vocab_size: int,
dim_feedforward:int = 512, dropout:float = 0.1):
super(Seq2SeqTransformer, self).__init__()
encoder_layer = TransformerEncoderLayer(d_model=emb_size, nhead=NHEAD,
dim_feedforward=dim_feedforward)
self.transformer_encoder = TransformerEncoder(encoder_layer, num_layers=num_encoder_layers)
decoder_layer = TransformerDecoderLayer(d_model=emb_size, nhead=NHEAD,
dim_feedforward=dim_feedforward)
self.transformer_decoder = TransformerDecoder(decoder_layer, num_layers=num_decoder_layers)
self.generator = nn.Linear(emb_size, tgt_vocab_size)
self.src_tok_emb = TokenEmbedding(src_vocab_size, emb_size)
self.tgt_tok_emb = TokenEmbedding(tgt_vocab_size, emb_size)
self.positional_encoding = PositionalEncoding(emb_size, dropout=dropout)
def forward(self, src: Tensor, trg: Tensor, src_mask: Tensor,
tgt_mask: Tensor, src_padding_mask: Tensor,
tgt_padding_mask: Tensor, memory_key_padding_mask: Tensor):
src_emb = self.positional_encoding(self.src_tok_emb(src))
tgt_emb = self.positional_encoding(self.tgt_tok_emb(trg))
memory = self.transformer_encoder(src_emb, src_mask, src_padding_mask)
outs = self.transformer_decoder(tgt_emb, memory, tgt_mask, None,
tgt_padding_mask, memory_key_padding_mask)
return self.generator(outs)
def encode(self, src: Tensor, src_mask: Tensor):
return self.transformer_encoder(self.positional_encoding(
self.src_tok_emb(src)), src_mask)
def decode(self, tgt: Tensor, memory: Tensor, tgt_mask: Tensor):
return self.transformer_decoder(self.positional_encoding(
self.tgt_tok_emb(tgt)), memory,
tgt_mask)Концептот на “Внимание” е да го реши проблемот со преведување на текст, пред 20тина години овој проблем бил решаван со комплексни алгоритми кои имале бројни проблеми, наједноставниот проблем била самата должина на речениците при превод, тие се менуваат и стануваат уште по очигледни кога користиме јазици кои имаат различен начин на пишување, за повеќе околу проблемите од класичните начини на превод без корисење на неуронски мрежи можи да прочитате тука.
Клучеви, Вредности
\[Vnimanie(Q, K, V) = \text{softmax}\left(\frac{Q K^T}{\sqrt{d_k}}\right) V\]8. SentencePiece
SentencePiece претставува бесплатна библиотека, со отворена лиценца создадена од Google, која се користи за работа со невронски мрежи. Нејзина цел е токенизација и детокеннизација на текст за системи за обработка на природен јазик. Тоа овозможува да се постави фиксна големина на вокабуларот пред тренирање на моделот, без потреба од јазично смецифични правила или разделување по празни места.
SentencePiece во себе комбинира 2 најчесто користени методи:
- Byte paie encoding - за компресија и предвидување на често користени парови од карактери
- Unigram - кој користи статистички модели за избор на оптимален сет на поединци
8.1 Unigram
Unigram е алгоритам за токенизација на под-зборови, каде што претпоставката е дека појавата на токен е независна од било кој од другите токени кои се појавиле претходно. Принципот на алгоритмот е заснован на теоријата на веројатност за сегментација на текстот. Користи ЕМ алгоритам тренирање и Viterbi алгоритам за кодирање на токените. Токенизацијата започнува од голем корпус на токени-кандидати и алгоритмот прво учи кои од нив најдобро го зграпчуваат значењето на податоците кои се користат при тренинг на мрежата. Unigram, всушност итеративно ги наоѓа и ги отстранува непотребните и помалку користените токени, оставајќи оптималхо множество на токени.
Тренирање
Под процесот тренирање се мисли учење на невронската мрежа (трансформерот) да преведува текст.
За овој чекор искористивме графичка картичка Nvidia RTX 4090 со 24 GB VRAM.
Моделот го трениравме 20 епохи, секоја епоха траеше околу еден час, после 20 епохи учење, моделот започна да покажува знаци на конвергенција (асимптотски паралелно со x оската).
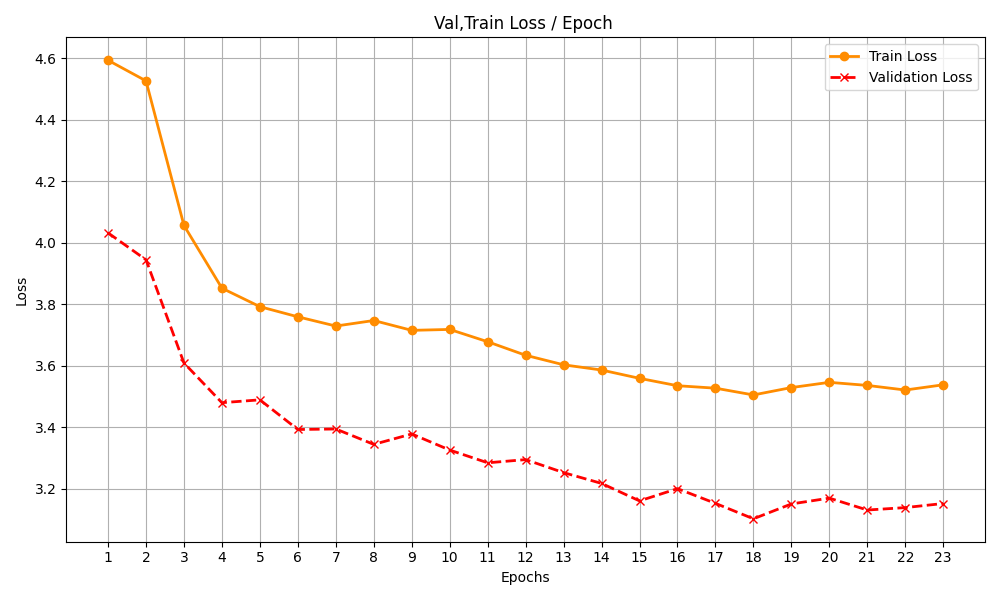
За Validation Loss беше користено 10% од податоците, со фиксиран seed за репордукција (42). Причината за толку мал примерок е тоа што dataset-от е веќе мал, а 30% се премногу податоци да бидат надвор за валидација а не тренирање. Можеби и затоа се толку лоши резултатите.
Според табелата која е прикажана како најдобар кандидат за инференца се покажа епоха 18, со најниска вредност на валидација, тажно е што вредностите се над 3.
Претпоставуваме дека направивме грешка со learning-rate или грешка што искуството може само да ни ја открие, доколку некој поискусен знае слободно нека не корегира.
| Epoch | Train Loss | Validation Loss |
|---|---|---|
| 1 | 4.593 | 4.0319 |
| 2 | 4.526 | 3.9444 |
| 3 | 4.056 | 3.6089 |
| 4 | 3.852 | 3.4798 |
| 5 | 3.792 | 3.4891 |
| 6 | 3.759 | 3.3927 |
| 7 | 3.729 | 3.3943 |
| 8 | 3.747 | 3.3443 |
| 9 | 3.715 | 3.3782 |
| 10 | 3.718 | 3.3259 |
| 11 | 3.678 | 3.2844 |
| 12 | 3.634 | 3.2948 |
| 13 | 3.603 | 3.2525 |
| 14 | 3.586 | 3.2174 |
| 15 | 3.559 | 3.1606 |
| 16 | 3.535 | 3.2004 |
| 17 | 3.527 | 3.1526 |
| 18 | 3.505 | 3.1024 |
| 19 | 3.529 | 3.1507 |
| 20 | 3.546 | 3.1696 |
| 21 | 3.536 | 3.1309 |
| 22 | 3.521 | 3.1388 |
| 23 | 3.538 | 3.1521 |
Архитектура на моделот
| Параметри | |
|---|---|
| Македонски вокабулар | 11,370 |
| Англиски вокабулар | 8,257 |
| Големина на embedding | 512 |
| Број на глави за внимание | 8 |
| FFN скриен слој (FFN_HID_DIM) | 512 |
| Големина на batch (BATCH_SIZE) | 4 |
| Број на енкодер слоеви | 3 |
| Број на декодер слоеви | 3 |
Резултати
Моделот е дефинитивно премал за реални апликации, со помали реченици добро се снаоѓа.
Лимитации
-
би се ставиле ние авторите како лимитација, како почетници во оваа сфера, скоро 2 месеци лутавме по документации за да ги научиме основите, претпоставуваме дека имаме грешки при разбирање, имплементација, како и тренирање и валидација на моделот, но сметам дека следната верзија на моделот ќе биде помоќна и корисна., дефинитивно има простор за подобрување.
-
Големината на Data-setот, 500 илјади пар реченици можеби звучат многу, но во пракса јазиците се покажуваат покомплексни од она што изгледаат на површина, дел од проблемот кои го воочивме е дека дури и моделите како GPT, Claude, LLAMA et al. , кои имаат десетици милијарди параметри, кои се тренирани на петабајти податоци, имаат проблеми и потешкотии со македонскиот јазик, не дека нашиот јазик не е богат, туку причината се недостаток на податоци во кванитет, за вакви проекти се потребни квалитетни и квантитетни паралелни преводи. Дефинитивно би направиле огромен отскок, доколку моделот беше трениран да речиме од 1 до 10 милиони квалитетни реченици и поголем број на епохи.
-
Како трета лимитација е пристапот до тренирање на хардвер, за овој проект потрошивме околу 20 евра на тренирање на моделот (за пристап до RTX 4090).
Простор за подобрување
Можеби е добро да се проба BERT архитектура или некоја сосема понова State Оf Тhe Аrt, која од една страна не бара голем број на податоци и не мора да се тренира од ништо, туку над неа со квалитетен Data-Set да се fine-тунира.
Demo
![]()
Моделот е лиценциран под Creative Commons Attribution Non Commercial 4.0
Моделот **МОЖЕ** да се користи за едукативни цели и истражувачки цели.
Моделот **НЕ** може да биде користен во комерцијални продукти.
Заклучок
Дефинитивно сметаме дека научивме и ја срушивме бариерата на илузија на моделите на Трансформери, бидејќи многу од нашите колеги и другари, имаат некој вид на страв и несигурност кон иднината, дека моделот наречен трансформер ќе започне да ги заменува со работни позиции, ние наспротив оптимистички гледаме дека потребата за луѓе и интелектуална работа ќе биде уште по интересна и достапна за секого. Оставаме на времето да ни покаже што понатака.
Благодарност до:
Би сакале да изразиме посебна благодарност на следниве личности и институции, кои безусловно ни помогнаа и подржаја, без нив проектов не би постоел, од бесценети ресурси по македонски јазик, од песни, книги па се до вести, нашиот модел не би научил да преведи ниту една реченица, затоа би сакале да им се заблагодариме на следниве личности и институции:
- Проф д-р Костандина Вељановска - ФИКТ - Битола.
- М-р Дарко Пајковски - Асистент - ФИКТ - Битола.
- Акад. Марјан Марковиќ - Дигитални ресурси на македонскиот јазик.
- Проф. д-р Георге Гоце Митревски - pelister.org.
- Ph.D Игор Трајковски - time.mk.
- pesna.org.
Литература/Референци:
- Attention is All You need.
- What Do Position Embeddings Learn?
- The Illustrated Transformer.
- Kemal Erdem, (May 2021). “Introduction to Attention Mechanism”
- theaisummer.com - Positional Embeddings
Download
- Модел Donka v1 - CC BY-NC 4.0 - Hugging Face .
- Изворен код - Github - Apache.
- Google Colab - Тестирање.
Корисна литература за почетници и за љубопитните:
Следниве ресурси се комплетно бесплатни и корисни за сите оние кои сакаат да научат кодирање, машинско учење, линеарна алгебра,веројатност и статистика.
Зошто овие теми, бидејќи со помош на овие теми и вие ќе можите да тренирате и да ги разбирате невронските мрежи и вештачката интелигенција.
- Линеарна Алгебра - Jim Hefferon - книга кој авторот ја нуди бесплатно.
- Целосен Roadmap за учење.
- Научете Python од MIT.
- Научете Python Интеракивно - Курс од Stanford.
- Научете Python - Курс од Harvard.
- Научете Линеарна Алгебра визуелно, делот со операции за вектори и матрици е многу важен во машинското учење - Immersive Math.
- Визуелно експериментирање со ** Tensorflow Deep Playground**.
- 3b1b - Невронски Мрежи.
- StatQuest - Статистика.